

こんにちは!
心が病みかけたITエンジニアのなかたつです。
今回は、「オブジェクト指向プログラミング」について解説していきます。
オブジェクト指向プログラミング(OOP)は、ソフトウェア開発において広く使われている手法です。
現実世界のモノや仕組みをモデル化してプログラムを作る考え方であり、プログラムの保守性や拡張性を高めることができます。
本記事では、オブジェクト指向プログラミングの基礎と重要な概念について解説します。
それでは参りましょう!
オブジェクト指向プログラミングについて
オブジェクト指向プログラミングとは
オブジェクト指向プログラミングは、「オブジェクト」という概念に基づいたプログラミングパラダイムの一つです。
オブジェクト指向は英語のobject orientedの訳語で、直訳すると「モノ指向」「モノ中心」です。
つまり、オブジェクト指向プログラミングとは、「モノ指向」「モノ中心」でプログラミングすることとなります。
オブジェクト指向プログラミングの目的
オブジェクト指向プログラミングの目的は、保守性や再利用性、拡張性の向上です。
オブジェクト指向が普及する以前は、過程指向プログラミングなどの「機能中心」の開発手法が主流でした。
「機能中心」の開発手法とは、対象とするシステム全体の機能をとらえ、それを段階的に詳細化して、より小さな部品に分解していく手法です。
この「機能中心」の開発手法でソフトウェアを作ると、仕様変更や機能追加が起きた場合の修正範囲が広範囲になりやすく、ソフトウェアの再利用も難しいという課題がありました。
オブジェクト指向はソフトウェアの保守や拡張、再利用をしやすくすることを重視する技術です。
個々の部品により強く着目し、部品の独立性を高め、それらを組み上げてシステム全体の機能を実現することを基本にします。
部品の独立性を高めることで、修正が起きた場合の影響範囲を最小限にし、他のシステムで容易に再利用できるようにします。
オブジェクト指向の基本概念
オブジェクト指向プログラミングは、以下の基本概念があります。
- クラス(カプセル化)
- 継承
- ポリモーフィズム
ここではそれぞれの詳細を簡単に説明します。
基本概念1:クラス(カプセル化)
オブジェクト指向の最も基本的な仕組みはクラスです。
クラスは英語のclassで「分類」「種類」といった「同種のモノの集まり」という意味を持ちます。
基本概要2:継承
継承の仕組みをひと言で表現すると「モノの種類の共通点と相違点を体系的に整理する仕組み」です。
オブジェクト指向では「モノの種類」はクラスのことなので、「似た者同士のクラスの共通点と相違点を整理する仕組み」と表現を変えることもできます。
基本概念3:ポリモーフィズム
ポリモーフィズムは英語で「いろいろな形に変わる」といった意味を持つ言葉で、日本語では「多態性」などと訳されます。
ポリモーフィズムの仕組みをひと言で表現すると「類似したクラスに対するメッセージの送り方を共通にする仕組み」と言えます。
オブジェクト指向プログラミングで保守性や再利用性、拡張性を向上させるためには、これらの基本概要をうまく利用する必要があります。
これらの基本概要は後ほど詳しく説明しますので、まずはオブジェクト指向が注目されるまでの歴史をみていきましょう。
オブジェクト指向の歴史と背景
オブジェクト指向言語が普及し始めた頃には、それ以前のものとは全く異なる新しい開発技術だと説明されることがよくありました。
しかし実際には、オブジェクト指向プログラミングはそれ以前のプログラミング技術を基礎として、その欠点を補うための技術と考える方が自然です。
長く続いてきたプログラミング技術の工夫と改良の歴史の中で、必然性を持って登場したものです。
そこで、ここではプログラミングが機械語として登場した時代まで遡って、オブジェクト指向プログラミングが誕生した歴史と背景を簡単に振り返ります。
これを理解できれば、オブジェクト指向が品質の良いプログラムを高い生産性で作るための実践的な技術であると納得できるでしょう。
黎明期には機械語でプログラムを書いていた
コンピュータは2進数で書いた機械語しか解釈できません。
そのためコンピュータを動かすには、最終的に機械語で書いた命令群を用意する必要があります。
1940年代、プログラマは機械語を使って1行1行プログラムを書いていました。
コンピュータの黎明期は、こうした機械語を使いこなせる、ごく限られたスーパープログラマだけがコンピュータを操れる時代でした。
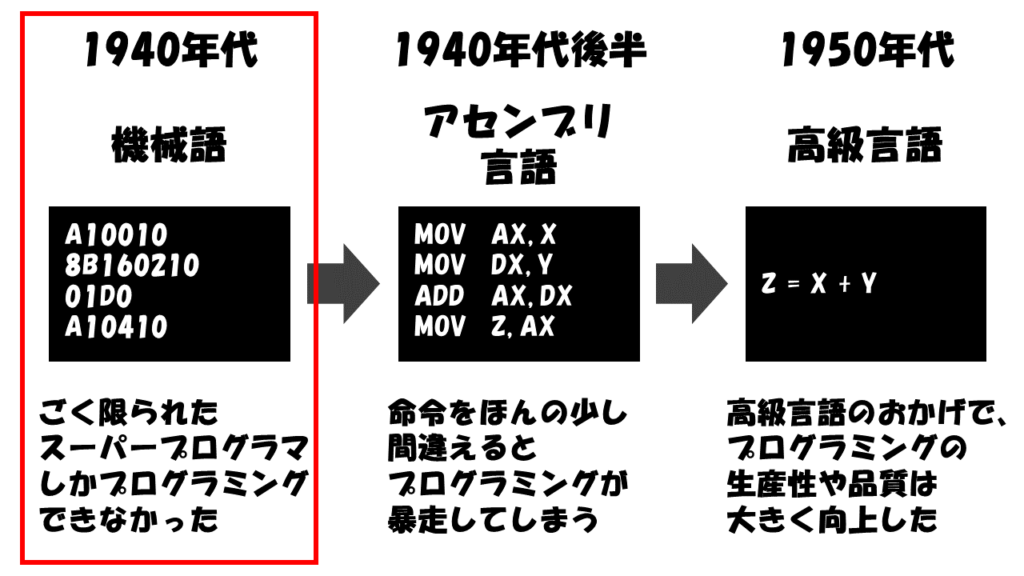
プログラミングの最初の一歩はアセンブリ言語
そこで、このような非効率なプログラミングを改善するためにアセンブリ言語が登場しました。
このアセンブリ言語こそがプログラミング言語の最初の一歩でした。
アセンブリ言語は、人間では理解が難しい機械語を、人間がわかりやすい記号に置き換えて表現します。
アセンブリ言語を使って書いたプログラムは、それをコンパイルするアセンブラと呼ばれる別のプログラムに読み込ませて機械語を生成します。
この発明により、プログラムが格段にわかりやすくなったことで、間違いも減り、修正も非常に楽になりました。
しかし、アセンブリ言語によるプログラミングでは、命令をほんの少し間違えただけでもプログラムは暴走してしまいました。
また、わかりやすくなったとはいえ、まだまだ生産性や品質は低いものでした。
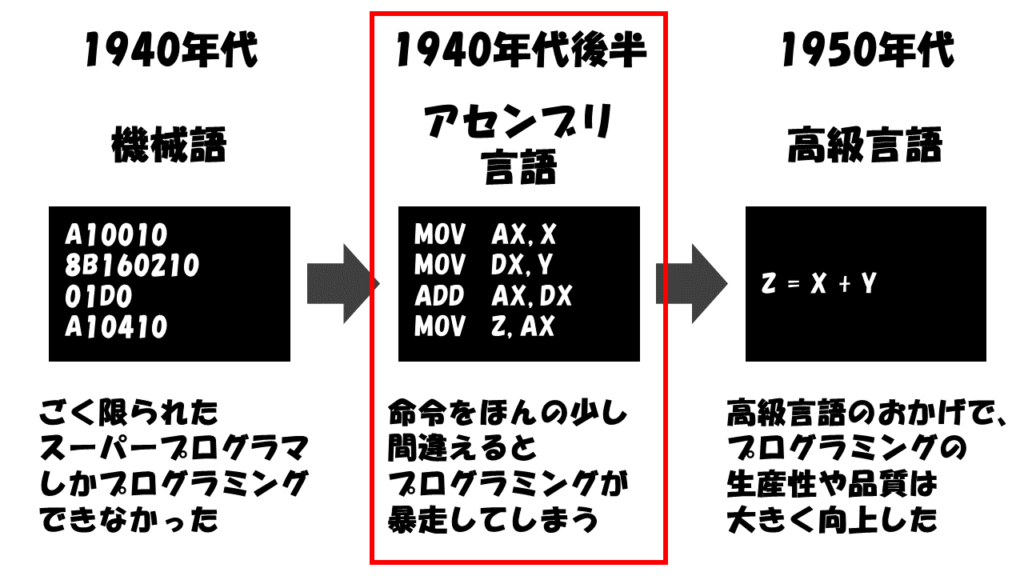
高級言語の発明でプログラムはより人間に近づいた
そこで、より人間に親しみやすい表現形式でプログラムを書くための高級言語が発明されました。
高級言語では、コンピュータが理解する命令を一つひとつ記述するのではなく、より人間にわかりやすい「高級な」形式で表現します。
高級言語の登場により、プログラミングの生産性や品質は大きく向上しました。
しかし、それ以上にコンピュータの普及と発展のほうが爆発的に進んだため、生産性向上に対するニーズは収まりませんでした。
1960年代後半にはNATO(北大西洋条約機構)の国際会議で「20世紀末には世界の総人口がプログラマになっても、増大するソフトウェアへの需要に追いつかない」という、ソフトウェア危機が宣言されたほどです。
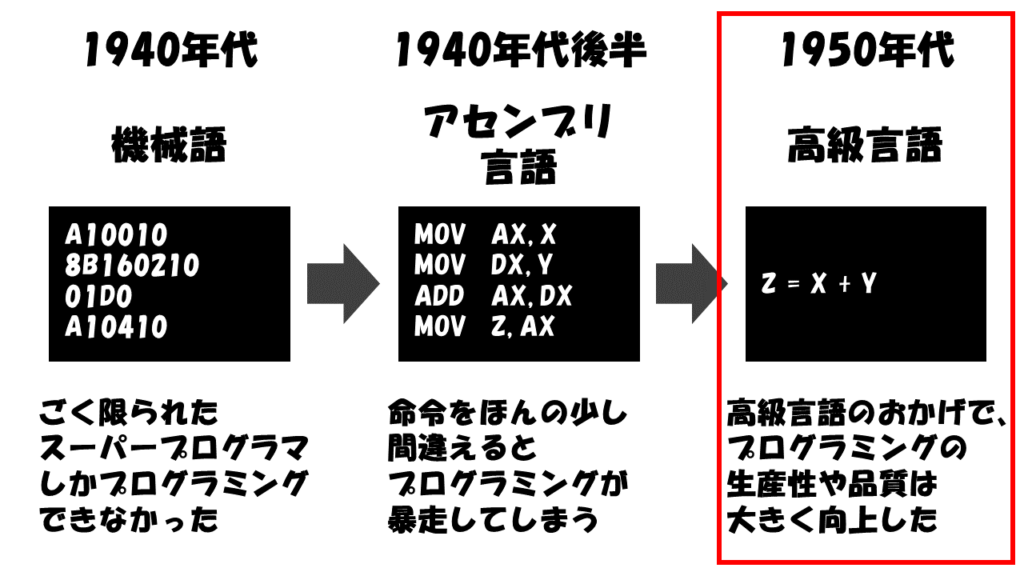
わかりやすさを重視する構造化プログラミング
このソフトウェア危機に対応するため、さまざまなアイデアや新しいプログラミング言語が提案されました。
その中で当時最も注目を集めたのが構造化プログラミングです。
構造化プログラミングは、オランダ人の学者であるエドガー・ダイクストラ氏によって提唱されました。
基本的な考え方は「正しく動作するプログラムを作成するためには、わかりやすい構造にすることが重要である」というものです。
具体的な方法として、プログラムをわかりづらくするGOTO文を廃止して、以下の基本三構造だけで表現することを提唱しました。
- 順次進行
- 条件分岐
- 繰り返し
順次進行
プログラムに書かれた命令を上から順に次々と実行させることです。
プログラムの最も基本的な動きになります。
条件分岐
「ある条件によって複数の処理のうちどれかを選択して実行する」ことを指します。
プログラミングではif文やswitch文が該当します。
繰り返し
「ある条件を満たすまで繰り返し処理を実行し、条件を満たしたら処理を終了する」ことです。
プログラミングではfor文やwhile文が該当します。
基本三構造の理論は非常に強力でありながら、シンプルで受け入れやすかったため、幅広く支持されました。

サブルーチンの独立性を高めて保守に強くする
もうひとつこの当時、プログラムを保守に強くするために工夫されたのが、サブルーチンの独立性を高めることです。
この仕組みは、プログラムの複数の場所に現れる共通処理を1ヵ所にまとめて、プログラムサイズを小さくし、プログラム作成の手間を減らすためのものです。
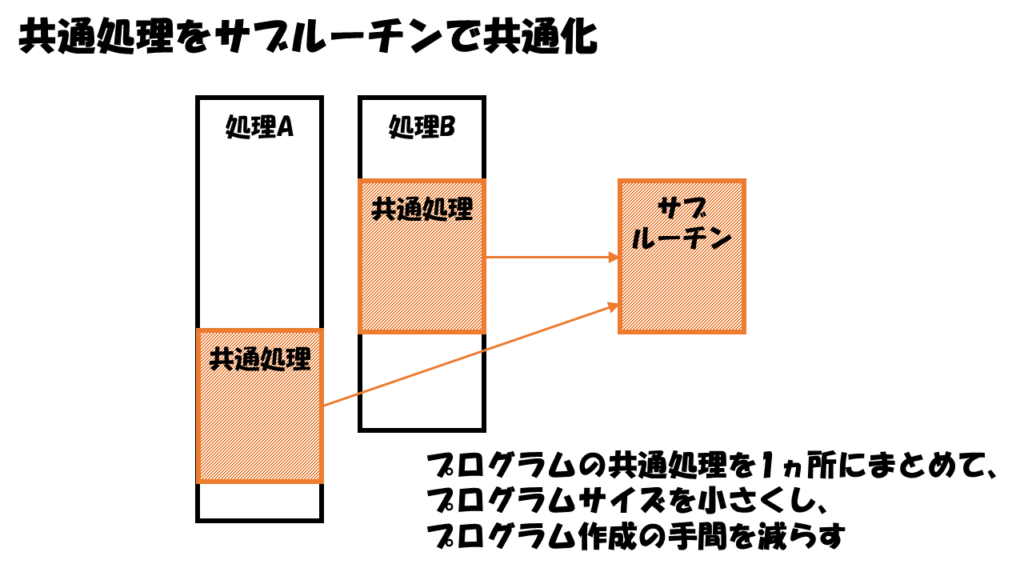
サブルーチンは1940年代にはすでに発明されていましたが、この時代になると、処理を共通化するだけでは不十分になりました。
プログラムの保守性を高めるためにはサブルーチンの独立性を高めることが重要だと認識されてきます。
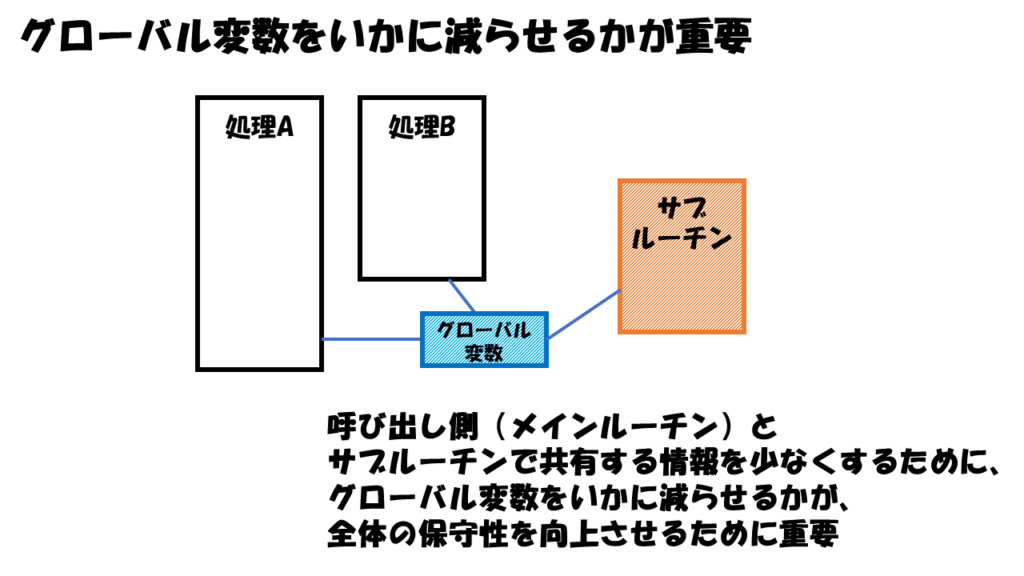
「サブルーチンの独立性を高める」とは、呼び出し側(メインルーチン)とサブルーチンで共有する情報を少なくすることです。
共有する情報とは、変数に格納されるデータを指します。
複数のサブルーチンが共有するこうした変数のことをグローバル変数と呼びます。
グローバル変数は、プログラム全体のどこからでもアクセスできるため、デバック時に変数の内容が不正なことがわかったりすると、すべてのソースコードを調べなければなりません。
そのため、グローバル変数をいかに減らせるか?が、全体の保守性を向上させるために重要だと認識されてきました。
こうした問題を避け、サブルーチンの独立性を高めるために以下2つの仕組みが考案されました。
- ローカル変数
- 引数の値渡し
ローカル変数
ローカル変数は、サブルーチンの中だけで使われる変数です。
この変数はサブルーチンに入ったときに作られて、サブルーチンから抜けるときには消える性質を持ちます。

引数の値渡し
引数の値渡しは、サブルーチンに引数として情報を渡す際に、呼び出し側が参照している変数を直接使わずに、値をコピーして渡す仕組みです。
サブルーチンの処理結果も戻り値として値渡しでやりとりすることで、呼び出し側が参照している変数に影響を及ぼさないようにします。
この仕組みを使えば、呼び出されたサブルーチン側で受け取った引数の値を変更しても、呼び出す側が参照している変数に影響を与えることがなくなります。

ローカル変数と値渡しの仕組みは、グローバル変数の使用を最小限にし、サブルーチン間で共通にアクセスする変数を減らすためのものです。
この仕組みをうまく使うことで、サブルーチンの独立性を高めることが可能になります。
残された課題はグローバル変数問題と貧弱な再利用
構造化プログラミングはプログラマにとって常識になりました。
しかし、構造化プログラミングでは解決できない2つの問題が残りました。
- グローバル変数問題
- 貧弱な再利用
グローバル変数問題
1つめはグローバル変数問題です。
構造化言語では、ローカル変数や値渡しの仕組みを導入したため、グローバル変数経由での情報の受け渡しを必要最小限に抑えることが可能になりました。
しかし、ローカル変数はサブルーチン呼び出しが終わると消えてしまう一時的な変数です。
サブルーチンの実行期間を超えて保持する必要のある情報は、グローバル変数として保持せざるをえませんでした。
プログラムの規模が大きくなればなるほど、このグローバル変数問題は深刻になります。
構造化言語ではこの問題を避けることが困難でした。
貧弱な再利用
もう1つの問題は貧弱な再利用です。
構造化言語で再利用できるのはサブルーチンでした。
この時代には、コード変換や入出力処理などの汎用ライブラリが提供され、基本的な処理については既存のプログラムを再利用することがある程度可能になりました。
しかし、増大するアプリケーションの規模全体からすると効果は限定的でした。
より大規模な再利用の必要性はソフトウェア開発者の共通認識でしたが、なかなか実現できませんでした。
これは共通部分として作れるのがサブルーチンだけだったことが大きな原因でした。

オブジェクト指向プログラミングが注目を浴びる
こうした問題を解決するのが、オブジェクト指向プログラミングです。
オブジェクト指向プログラミングはすでに1967年にSimula67として姿を表していました。
しかし、当時のハードウェアの能力不足や、あまりの先進性のため、長い間一部の研究機関を中心に細々と使われていただけでした。
状況が変わったのは、1980年代にGUIを備えたワークステーション上で動作する商用のSmalltalkが登場してからです。
それからC言語の発展形としてC++が考案され、GUIライブラリの開発で柔軟性と再利用性が実証されはじめた頃から徐々に頭角を表してきました。
そして、1990年代のインターネットブームの中でJavaが登場してからオブジェクト指向プログラミングは一気に主役の座に踊り出ました。
冒頭に、オブジェクト指向プログラミングは「それ以前のプログラミング技術を基礎として、その欠点を補うための技術」と説明しましたが、納得できましたか?
オブジェクト指向プログラミングは、構造化プログラミングでは解決できなかった問題を解決するために、必然性を持って登場しました。
この事実を知ってオブジェクト指向の概念を改めて学ぶと、一度オブジェクト指向の難しさで挫折した人もすんなりと理解できるかと思います。
オブジェクト指向の重要な概念
オブジェクト指向プログラミングにはそれ以前のプログラミングにはない3つの優れた仕組みが備わっています。
これは、「クラス(カプセル化)」、「ポリモーフィズム」、「継承」の3つで、オブジェクト指向プログラミングが普及し始めた1990年代には、これらをオブジェクト指向プログラミングの三大要素と呼んでいました。
オブジェクト指向プログラミングが主役の座に踊り出るきっかけとなった、構造化プログラミングでは解決できない「グローバル変数問題」、「貧弱な再利用」という2つの課題がありましたが、オブジェクト指向プログラミングの三大要素は、まさにこの課題を解決するためのものです。
- オブジェクト指向プログラミングにはグローバル変数を使わずに済ませる仕組みが備わっている。
- オブジェクト指向プログラミングには共通サブルーチン以外の再利用を可能にする仕組みが備わっている。
オブジェクト指向プログラミングの3つの仕組みは、「プログラムの無駄を省いて整理整頓するための仕組み」と言えます。
つまり、オブジェクト指向プログラミングの3つの仕組みは、重複した無駄なロジックを排除し、必要な機能を整理整頓する仕組みをプログラマに提供してくれます。
それではそれぞれの要素について詳しく説明します。
三大要素1:クラス(カプセル化)に備わる3つの仕組み
まずは三大要素の1番目としてクラスを説明します。
クラスには3つの仕組みが備わっています。
- サブルーチンと変数を「まとめる」
- クラスの内部だけで使う変数やサブルーチンを「隠す」(カプセル化)
- 1つのクラスからインスタンスを「たくさん作る」
クラスの仕組み1:サブルーチンと変数を「まとめる」
最初の「まとめる」仕組みからです。
まずはグローバル変数とサブルーチンしかなかった場合の状況から確認していきましょう。

グローバル変数とサブルーチンの間には何も境界線がないので、パッと見て「何のためのグローバル変数なのか?」、「何のためのサブルーチンなのか?」が分かりません。
次にクラスで「まとめる」場合を見ていきましょう。

クラスで、グローバル変数とサブルーチンをまとめました。
クラスにより境界線ができただけでなく、結びつきの強いグローバル変数とサブルーチンをまとめることで、パッと見て「何のためのグローバル変数なのか?」、「何のためのサブルーチンなのか?」が分かるようになりました。
ちなみに、クラス内では「グローバル変数⇒インスタンス変数(別名は属性、フィールド)」、「サブルーチン⇒メソッド」と名称が変わっています。
これはオブジェクト指向プログラミングでクラスにまとめた場合のそれぞれの名称となります。
次に、実際のコードでも確認してみましょう。
まずはグローバル変数とサブルーチンしかなかった場合のコードとなります。
// 犬と猫のそれぞれの名前を格納するグローバル変数
string nameDog;
string nameCat;
// 犬が眠るサブルーチン
void sleepDog(){ /* ロジックは省略 */}
// 犬が鳴くサブルーチン
void cryDog(){ /* ロジックは省略 */}
// 猫が眠るサブルーチン
void sleepCat(){ /* ロジックは省略 */}
// 猫が鳴くサブルーチン
void cryCat(){ /* ロジックは省略 */}次にクラスで「まとめる」場合のコードを見ていきましょう。
// 犬クラス
class Dog {
// 犬の名前を格納するインスタンス変数
String name;
// 犬が眠るメソッド
void sleep(){ /* ロジックは省略 */}
// 犬が鳴くメソッド
void cry(){ /* ロジックは省略 */}
}
// 猫クラス
class Cat {
// 猫の名前を格納するインスタンス変数
String name;
// 猫が眠るメソッド
void sleep(){ /* ロジックは省略 */}
// 猫が鳴くメソッド
void cry(){ /* ロジックは省略 */}
}いかがでしょうか?
ただサブルーチンと変数を結びつきの強いクラスにまとめただけです。
しかし、まとめて整理整頓することに価値があります。
まとめることで、以下3つの効果があります。
- PGが理解しやすい
- メソッド(サブルーチン)の名前づけが楽になる
- メソッド(サブルーチン)が探しやすくなる
効果1:PGが理解しやすい
1つ目の効果は、PGが理解しやすくなることです。
クラス内には、クラスに必要な変数やメソッドしか存在しません。
つまり、結びつきの強い情報が集まっているので、そのクラスで「何がしたいのか?」「何ができるのか?」を理解しやすくなります。
効果2:メソッド(サブルーチン)の名前づけが楽になる
2つ目の効果は、メソッド(サブルーチン)の名前づけが楽になることです。
クラスがない構造化言語では、すべてのサブルーチンに違う名前をつけなければいけません。(「sleepDog」や「sleepCat」など)
しかし、クラスに格納するメソッドの名前は、クラス内で重複しなければよいルールになっています。
そのため、重複をなくすための冗長的な名前づけがなくなり、適切な名前をつけることができます。(「sleepDog」や「sleepCat」が「sleep」だけでよくなる)
効果3:メソッド(サブルーチン)が探しやすくなる
3つ目の効果は、メソッド(サブルーチン)が探しやすくなることです。
適切な名前をつけたクラスにメソッドをまとめることは、メソッドを探しやすくする効果もあります。
これは一見地味に感じますが、再利用を促進するための重要な機能のひとつです。
いくら使い勝手が良く品質の高いサブルーチンを作ったとしても、数が多くて見つけられなければ意味がありません。
作ったものを後から探しやすければ、それだけ再利用がしやすくなります。
クラスの仕組み2:クラスの内部だけで使う変数やサブルーチンを「隠す」(カプセル化)
次は2つ目の「隠す」仕組み(カプセル化)です。
先ほどのコードで、サブルーチンとグローバル変数をDogクラスとCatクラスにまとめました。
しかし、この状態ではそれぞれのname変数はクラスの外側からアクセスできてしまいます。
それぞれのname変数は、DogクラスやCatクラスにまとめたsleep/cryメソッドからアクセスしますが、そのほかの処理からアクセスする必要はありません。
このため、それぞれのname変数にアクセスできる範囲を、クラスで管理するメソッドだけに限定したくなります。
そうすることで、これらの変数におかしな値が入ったことが原因となり、プログラムの不具合が発生した場合には、クラスで管理するメソッドだけを調べればよくなります。
また、後から変数の型を変更するなどの修正が必要になった場合にも、変更による影響範囲を限定できます。
オブジェクト指向プログラミングでは、インスタンス変数にアクセスできる範囲をそのクラス内だけに限定する機能が備わっています。
-1024x576.png)
インスタンス変数をクラス内に「隠した」場合のコードです。
// 犬クラス
class Dog {
// 犬の名前を格納するインスタンス変数
private String name;
// 犬が眠るメソッド
void sleep(){ /* ロジックは省略 */}
// 犬が鳴くメソッド
void cry(){ /* ロジックは省略 */}
}
// 猫クラス
class Cat {
// 猫の名前を格納するインスタンス変数
private String name;
// 猫が眠るメソッド
void sleep(){ /* ロジックは省略 */}
// 猫が鳴くメソッド
void cry(){ /* ロジックは省略 */}
}インスタンス変数を宣言している部分の先頭に「private」とつけただけです。
これが隠す仕組みです。
この指定により、それぞれのインスタンス変数へのアクセスは、クラス内部のメソッドだけに限定できました。
もはやこの変数はグローバルではありません。
オブジェクト指向プログラミングでは、変数やメソッドを隠すだけでなく、明示的に公開する機能も備わっています。
次に、クラスとメソッドを明示的に公開した場合のコードです。
// 犬クラス
public class Dog {
// 犬の名前を格納するインスタンス変数
private String name;
// 犬が眠るメソッド
public void sleep(){ /* ロジックは省略 */}
// 犬が鳴くメソッド
public void cry(){ /* ロジックは省略 */}
}
// 猫クラス
public class Cat {
// 猫の名前を格納するインスタンス変数
private String name;
// 猫が眠るメソッド
public void sleep(){ /* ロジックは省略 */}
// 猫が鳴くメソッド
public void cry(){ /* ロジックは省略 */}
}ここでは、クラスとメソッドの宣言部に「public」とつけただけです。
この指定により、これらはアプリケーションのどこからでも呼び出すことが可能になりました。
クラスの仕組み3:1つのクラスからインスタンスを「たくさん作る」
最後は「たくさん作る」仕組みです。
この「たくさん作る」仕組みは、従来のプログラミング言語では実現が難しいオブジェクト指向プログラミング特有の機能です。
この仕組みの鍵を握るのは、インスタンスです。
インスタンスとは、「クラスに基づいて生成された実体」のことです。
PGが動作するときの視点で説明すると、「クラスで定義したインスタンス変数が確保されるメモリ領域」と考えられます。
そして、このインスタンスはクラスを定義しておけばそこから実行時にいくつでも作ることができます。
つまり、いくつでもメモリ領域を確保することができます。
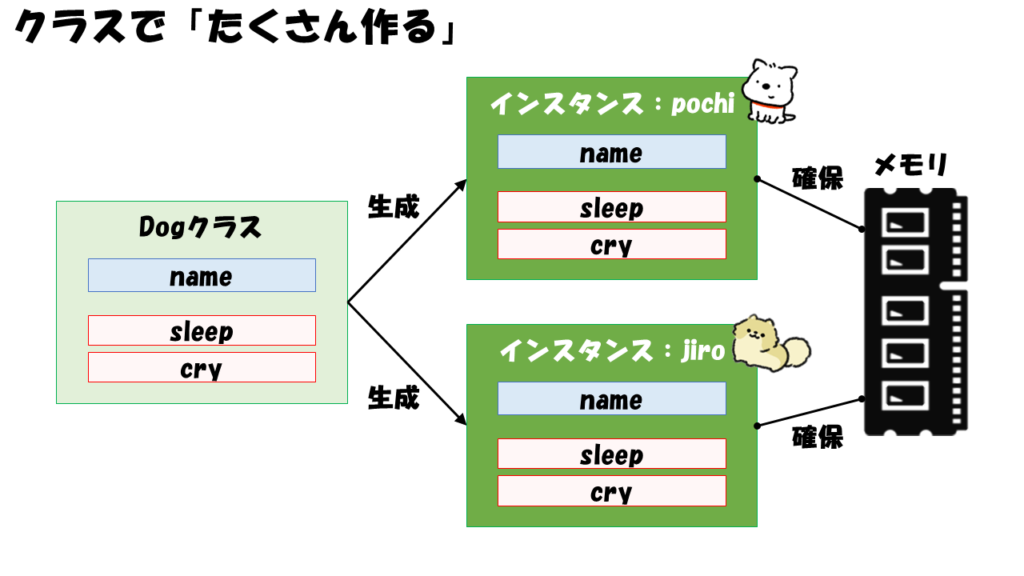
しかし、インスタンスを同時に複数作った場合に、各インスタンスのメソッドをどのように呼び分ければいいのでしょうか?
この問題を解決するために、オブジェクト指向プログラミングのメソッド呼び出しのコーディングは少し特別な書き方をします。
従来のサブルーチン呼び出しの場合は、たんに呼び出すサブルーチン名を指定するだけでした。
しかし、オブジェクト指向プログラミングの場合は、呼び出すメソッド名に加えて、対象とするインスタンスを指定します。
Javaの文法では、次のようにインスタンスを格納する変数名にピリオド(.)をつけて、その後にメソッド名を書きます。
それではサンプルコードを見てみましょう。
DogクラスやCatクラスを呼び出す側のコードです。
// Dogクラスから2つのインスタンスを作る
Dog pochi = new Dog(); // Dogクラスから"ポチ"のインスタンスを生成
Dog jiro = new Dog(); // Dogクラスから"ジロー"のインスタンスを生成
pochi.sleep(); // ポチが眠る
jiro.sleep(); // ジローが眠る
pochi.cry(); // ポチが鳴く
jiro.cry(); // ジローが鳴く
// Catクラスから2つのインスタンスを作る
Cat tama = new Cat(); // Catクラスから"タマ"のインスタンスを生成
Cat mike = new Cat(); // Catクラスから"ミケ"のインスタンスを生成
tama.sleep(); // タマが眠る
mike.sleep(); // ミケが眠る
tama.cry(); // タマが鳴く
mike.cry(); // ミケが鳴くここでは、最初にDogクラスとCatクラスからインスタンスを生成しています。
Dogクラスのインスタンスはpochiとjiroの変数に格納し、Catクラスのインスタンスはtamaとmikeに格納しています。
そして、sleep/cryメソッドを起動するときには、変数pochiやjiro、tamaやmikeを指定して呼び出しています。
このようにしてオブジェクト指向プログラミングでは、メソッドを呼び出すときにはどのインスタンスを対象にするのか指定する必要があります。
また、インスタンスごとに変数を管理できる仕組みのおかげで、クラスに書くメソッドのロジックは単純になります。
これは、変数を定義するクラス側では、インスタンスが複数同時に動くことを意識する必要がないことを意味します。
このような仕組みがない従来の言語で同じ機能を実現する場合、配列などを使って変数を複数管理する必要があるため(今回のサンプルコードでいえば、pochiとjiroのnameをそれぞれ配列で管理する)、それを処理するサブルーチンのロジックも複雑になってしまいます。(配列からpochiかjiroのnameを取得して、配列の値を更新する必要がある)
一般的にアプリケーションでは同種の情報(ファイルや文字列、GUIのボタンやテキストボックス、ビジネスアプリケーションの顧客や社員や商品など)を複数同時に扱う場合がよくあるため、この仕組みは非常に強力です。
オブジェクト指向プログラミングの場合、この仕組みを実現するために必要な事は、クラスを定義してインスタンスを生成するだけです。
最後にクラスの仕組みをまとめました。
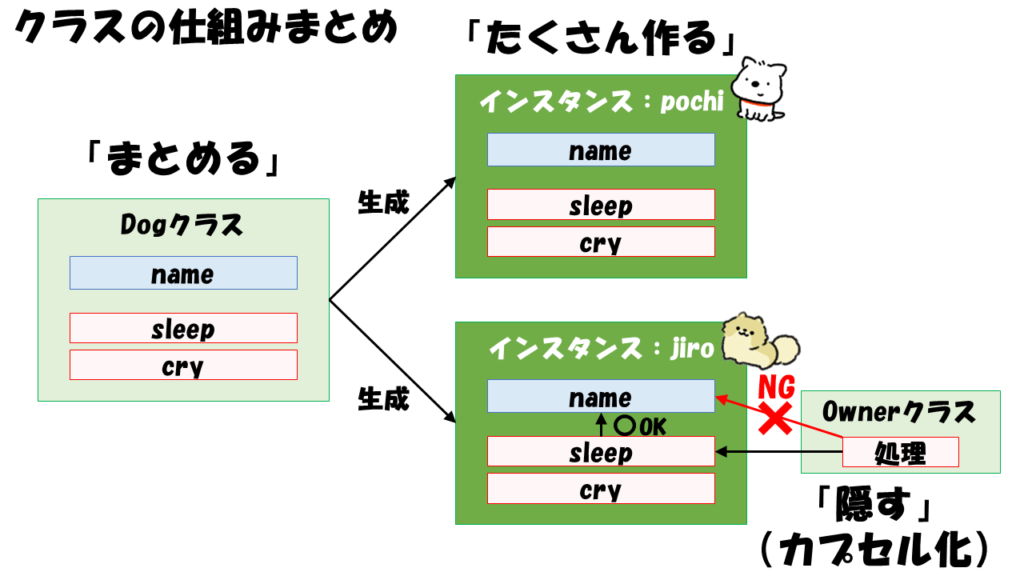
クラスの仕組みは、プログラムを作るうえで従来の言語にはなかった便利な機能を提供してくれます。
クラスがもたらすこれらのメリットを理解して使いこなしましょう。
三大要素2:クラス定義の重複を排除する継承
次に最大要素の2つめとして継承を説明します。
継承はひと言で表現すると「クラスの共通部分を別クラスにまとめる仕組み」と言えます。
この仕組みを利用することで、変数とメソッドをまとめた共通クラスを作り、別のクラスからその定義を丸ごと引き継ぐことが可能になります。
オブジェクト指向プログラミングでは、この共通クラスをスーパークラスと呼び、それを利用するクラスのことをサブクラスと呼びます。
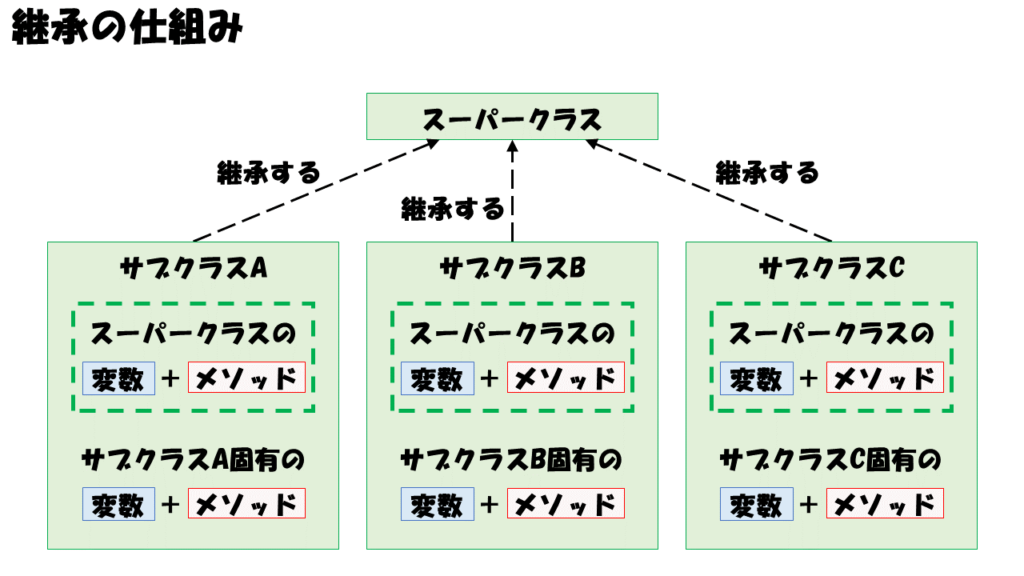
継承を使う場合、スーパークラスに共通に使いたいメソッドとインスタンス変数を定義し、サブクラスでスーパークラスを「継承すること」を宣言します。
この宣言だけで、スーパークラスの定義内容がそのまま使えるようになります。
それでは、実際のコードで確認してみましょう。
// 動物クラス(スーパークラス)
public class Animal {
// 動物の名前を格納するインスタンス変数
private String name;
// 動物が眠るメソッド
public void sleep(){ /* ロジックは省略 */}
// 動物が鳴くメソッド
public void cry(){ /* ロジックは省略 */}
}
// 犬クラス(サブクラス)
public class Dog extends Animal {
// 簡略化のためコンストラクタは省略
}
// 猫クラス(サブクラス)
public class Cat extends Animal {
// 簡略化のためコンストラクタは省略
}先ほどのDogクラスとCatクラスのスーパークラスとしてAnimalクラスを作成しました。
DogクラスとCatクラスがAnimalクラスを「継承すること」を宣言するために、各クラスに「extends」とスーパークラス名であるAnimalとつけただけです。
また、サブクラスであるDogクラスとCatクラスの共通部分をAnimalクラスに移すことで、DogクラスとCatクラスのコードを削減することができました。
これが継承の威力です。
継承の仕組みにより、重複したコードを排除することで保守性を向上させることができます。
三大要素3:呼び出す側を共通化するポリモーフィズム
最後に最大要素の3つめとしてポリモーフィズムを説明します。
ポリモーフィズムは英語で「いろいろな形に変わる」といった意味を持つ言葉で、日本語では「多態性」などと訳されます。
ポリモーフィズムの仕組みをひと言で表現すると、共通メインルーチンを作るための仕組みと言えます。
共通サブルーチンは呼び出される側のロジックを1つにまとめますが、ポリモーフィズムは呼び出す側のロジックを1本化します。
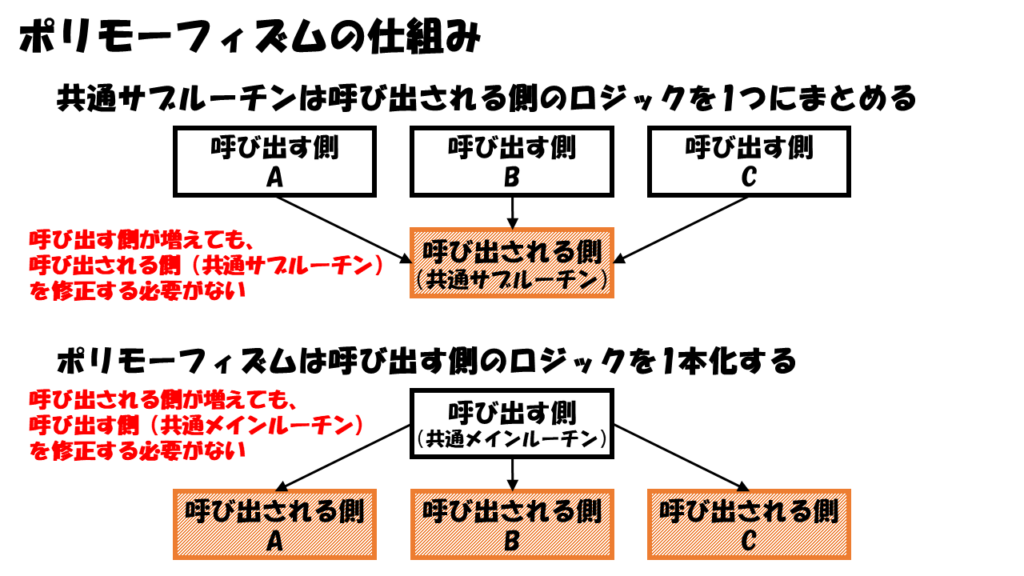
ポリモーフィズムはサブルーチンの呼び出し側を共通化しますが、とても重要な仕組みです。
オブジェクト指向プログラミングが登場するまで、共通サブルーチンはありましたが、共通メインルーチンはありませんでした。
フレームワークやクラスライブラリなども、このポリモーフィズムのおかげで可能になったものです。
それでは、実際のコードで確認してみましょう。
// 飼い主クラス
public class Owner {
// 動物に眠るように指示する
public void askToSleep(Animal animal) {
animal.sleep();
}
// 動物に鳴くように指示する
public void askToCry(Animal animal) {
animal.cry();
}
}
// 動物クラス(スーパークラス)
public class Animal {
// 動物の名前を格納するインスタンス変数
private String name;
// 動物が眠るメソッド
public void sleep(){ /* ロジックは省略 */}
// 動物が鳴くメソッド
public void cry(){ /* ロジックは省略 */}
}
// 犬クラス(サブクラス)
public class Dog extends Animal {
// 簡略化のためコンストラクタは省略
// 犬が鳴く
public void cry() {
System.out.println("ワンワン");
}
}
// 猫クラス(サブクラス)
public class Cat extends Animal {
// 簡略化のためコンストラクタは省略
// 猫が鳴く
public void cry() {
System.out.println("ニャーニャー");
}
}犬と猫では鳴き方が違うので、DogクラスとCatクラスそれぞれに固有のcryメソッドを用意しました。(呼び出される側)
また、飼い主として犬と猫に指示を出すOwnerクラスも追加しています。(呼び出す側)
頭の整理のために今の概要を図示してみました。
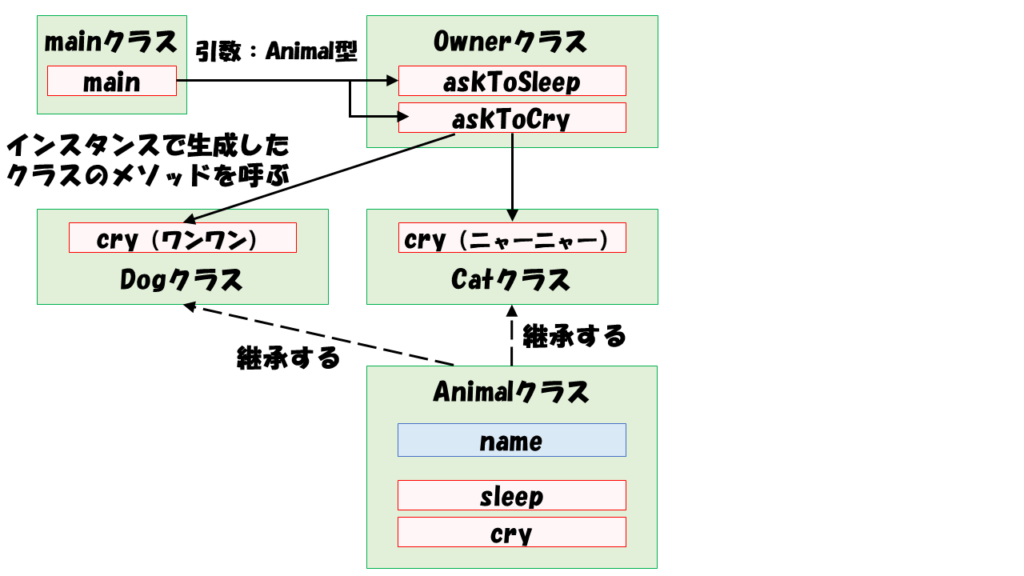
それでは、いよいよOwnerクラスからDogクラスとCatクラスを呼び出しすコードです。
// Ownerクラスから"飼い主"のインスタンスを作る
Owner owner = new Owner();
// DogクラスとCatクラスからインスタンスを作る
Animal pochi = new Dog(); // Dogクラスから"ポチ"のインスタンスを生成
Animal tama = new Cat(); // Catクラスから"タマ"のインスタンスを生成
// "飼い主"から"ポチ"と"タマ"に鳴くように指示する
owner.askToCry(pochi); // ポチに鳴くように指示する
owner.askToCry(tama); // タマに鳴くように指示するOwnerクラスのaskToSleep/askToCryメソッドの引数の型をスーパークラス(今回はAnimalクラス)にすることがポイントです。
ポリモーフィズムによって、サブクラスのインスタンスに定義されたメソッドが呼ばれることになります。
それでは、いよいよサブクラスにBirdクラスを追加してみましょう。
// 飼い主クラス
public class Owner {
// 動物に眠るように指示する
public void askToSleep(Animal animal) {
animal.sleep();
}
// 動物に鳴くように指示する
public void askToCry(Animal animal) {
animal.cry();
}
}
// 動物クラス(スーパークラス)
public class Animal {
// 動物の名前を格納するインスタンス変数
private String name;
// 動物が眠るメソッド
public void sleep(){ /* ロジックは省略 */}
// 動物が鳴くメソッド
public void cry(){ /* ロジックは省略 */}
}
// 犬クラス(サブクラス)
public class Dog extends Animal {
// 簡略化のためコンストラクタは省略
// 犬が鳴く
public void cry() {
System.out.println("ワンワン");
}
}
// 猫クラス(サブクラス)
public class Cat extends Animal {
// 簡略化のためコンストラクタは省略
// 猫が鳴く
public void cry() {
System.out.println("ニャーニャー");
}
}
// 鳥クラス(サブクラス)
public class Bird extends Animal {
// 簡略化のためコンストラクタは省略
// 鳥が鳴く
public void cry() {
System.out.println("ちゅんちゅん");
}
}Birdクラスを追加したときの概略図です。
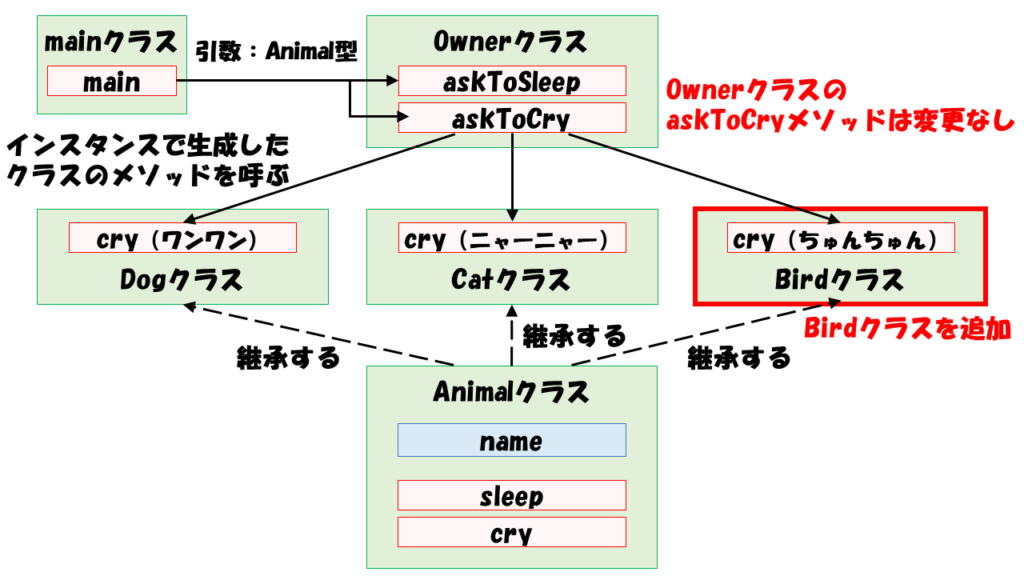
では、鳥に鳴くように指示を追加してみましょう。
// DogクラスとCatクラスからインスタンスを作る
Animal pochi = new Dog(); // Dogクラスから"ポチ"のインスタンスを生成
Animal tama = new Cat(); // Catクラスから"タマ"のインスタンスを生成
Animal suzume = new Bird(); // Birdクラスから"スズメ"のインスタンスを生成
// Ownerクラスからインスタンスを作る
Owner owner = new Owner();
owner.askToCry(pochi); // ポチに鳴くように指示する
owner.askToCry(tama); // タマに鳴くように指示する
owner.askToCry(suzume); // スズメに鳴くように指示する呼び出す側(共通メインルーチン)であるOwnerクラスは一切変更していません。
これがポリモーフィズムの威力です。
この仕組みこそが、オブジェクト指向プログラミングを使う理由といっても過言でないでしょう。
オブジェクト指向プログラミングの目的は、保守性や再利用性、拡張性の向上です。
これらの目的を達成するための手段として、オブジェクト指向の基本概念である「クラス(カプセル化)」、「継承」、「ポリモーフィズム」があります。
「クラス(カプセル化)」で結びつきの強い変数とサブルーチンをまとめて、変数やメソッドへのアクセス制限をかけ、インスタンスでたくさん作ることができ、「継承」で似たようなクラスの共通部分をまとめてしまい、「ポリモーフィズム」で呼び出し側を一本化しています。
まさに徹底した合理化。
重複した無駄なロジックを排除し、必要な機能を整理整頓する仕組みを提供するのがオブジェクト指向プログラミングです。
オブジェクト指向プログラミングの種類と言語
必然性を持って登場したオブジェクト指向プログラミングですが、今では様々な言語で実装されています。
それぞれの特徴を理解し、適切な言語を選択することが重要です。
代表的なオブジェクト指向言語(Java, Python, C#)
Java
- Javaは、世界で最も広く使用されているオブジェクト指向言語の一つです。
- 高い安全性と信頼性を備えており、エンタープライズアプリケーションやWebアプリケーションによく使用されます。
- 豊富なライブラリとフレームワークが用意されており、開発効率を向上させることができます。
Python
- Pythonは、初心者でも比較的習得しやすいオブジェクト指向言語です。
- シンプルで読みやすい構文を持ち、Webスクレイピングやデータ分析などのタスクによく使用されます。
- 機械学習や人工知能の分野でも広く使用されています。
C#
- C#は、.NET Framework上で動作するオブジェクト指向言語です。
- ゲーム開発やデスクトップアプリケーション開発によく使用されます。
- 高いパフォーマンスと拡張性を備えています。
その他の代表的なオブジェクト指向言語
- C++
- C
- Ruby
- JavaScript
オブジェクト指向プログラミングは、現代のプログラミングにおいて最も重要なパラダイムの一つです。
様々な種類のオブジェクト指向言語があり、それぞれの特徴を理解して、適切な言語を選択することが重要です。
オブジェクト指向プログラミングのデメリット
ここまでオブジェクト指向の重要な概念からオブジェクト指向プログラミングがもたらす様々なメリットを説明してきました。
ここではデメリットにも目を向けてみましょう。
デメリットは以下の点です。
- メモリ消費量が多くなる
- 処理速度が遅くなる可能性がある
デメリット1:メモリ消費量が多くなる
オブジェクト指向プログラミングは、従来の手続き型プログラミングと比べて、メモリ消費量が多くなる傾向があります。
その理由は以下の通りです。
- インスタンスごとにメモリを確保:同じクラスから生成されたインスタンスであっても、それぞれ独立したメモリ領域を必要とします。
- 継承関係によるメモリ増加:サブクラスはスーパークラスのデータを継承するため、メモリ消費量が増加します。
しかし、近年では以下の理由により、メモリ消費量の増加が問題になるケースは少なくなっています。
- ハードウェア性能の向上:メモリ容量や処理速度が向上したため、以前よりも多くのオブジェクトを扱うことが可能になりました。
- ガベージコレクションの導入:多くのオブジェクト指向プログラミングでは、不要になったオブジェクトを自動的に解放するガベージコレクション機能が搭載されています。
また、メモリ消費量を節約するために、以下のような対策も有効です。
- 軽量オブジェクトの使用:必要最低限のデータとメソッドのみを持つ軽量オブジェクトを使用することで、メモリ消費量を削減できます。
- オブジェクトの参照カウンティング:オブジェクトへの参照数をカウントし、参照されなくなったオブジェクトを自動的に解放する仕組みです。
- オブジェクトプーリング:頻繁に使用するオブジェクトをプールすることで、生成と解放に伴うオーバーヘッドを削減できます。
デメリット2:処理速度が遅くなる可能性がある
以下のような場合には、オブジェクト指向プログラミングが処理速度を低下させる可能性があります。
- 過剰なオブジェクト生成:必要以上に多くのオブジェクトを生成すると、メモリ消費量が増加し、処理速度が低下する可能性があります。
- 複雑なオブジェクト構造:複雑なオブジェクト構造を持つ場合、オブジェクト間の参照関係を処理するのに時間がかかり、処理速度が低下する可能性があります。
ただし、オブジェクト指向プログラミングは手続き型プログラミングと比べて処理速度が遅くなるという誤解もあります。
確かに、オブジェクトの生成やメソッド呼び出しには、手続き型プログラミングよりも多くの処理が必要となりますが、現代のCPUは十分な処理速度を備えています。
多くの場合において、この処理速度の差は目に見えません。
むしろ、オブジェクト指向プログラミングは以下の点で処理速度の向上に貢献することもあります。
- コードのモジュール化:オブジェクト指向のコードは、モジュール化されやすく、再利用性が高いです。そのため、複雑なプログラムを効率的に開発・保守することができ、結果的に処理速度の向上につながります。
- アルゴリズムの選択:オブジェクト指向プログラミングは、問題を解決するための適切なアルゴリズムを選択しやすくなっています。適切なアルゴリズムを選択することで、処理速度を大幅に向上させることができます。
オブジェクト指向プログラミングのデメリットを説明しました。
しかし、これらのデメリットもメモリやCPUなどのハードウェア性能が向上したことで、誤差程度になっています。
そのため、これらのデメリットが問題になるとしたら、やはり、設計に問題があることが多いでしょう。
オブジェクト指向の設計と開発
では、どのように設計すればいいのでしょうか?
ここでは、オブジェクト指向設計の基本として、デザインパターンという設計手法を簡単に説明します。
オブジェクト指向設計の基本パターン
デザインパターンとは、オブジェクト指向プログラミングでよく使われる設計手法のテンプレートのようなものです。
プログラミングしていると、以前と同じことを繰り返していると気づくことがあります。
経験が増すにつれ、そのような「パターン」が自分の中に数多く蓄積され、やがてその「パターン」を次の開発に当てはめていくことができるようになります。
Erich Gamma (エーリヒ・ガンマ)、Richard Helm (リチャード・ヘルム)、Ralph Johnson (ラルフ・ジョンソン)、John Vlissides (ジョン・ヴリシディス)の4人が、そのような開発者の「経験」や「内的な蓄積」としてまとめたパターンを、「デザインパターン」という形に整理しました
デザインパターンは全部で23個ありますが、ここでは3種類に分類したうえで、19個に絞って紹介します。
生成パターン
- Factory Method パターン:特定のクラスのインスタンス生成をカプセル化するパターンです。具体的な生成方法を知らなくてもオブジェクト生成が可能になり、コードの変更を最小限に抑えながら柔軟性を高めることができます。
- Abstract Factory パターン:複数の関連するクラスのインスタンス生成をカプセル化するパターンです。Factory Method パターンを拡張し、より複雑な生成処理に対応することができます。
- Builder パターン:複雑なオブジェクトを段階的に構築していくパターンです。複数の部品を組み合わせてオブジェクトを生成することで、柔軟性と可読性を向上させることができます。
- Prototype パターン:オブジェクトを複製することで新しいオブジェクトを生成するパターンです。既存のオブジェクトをテンプレートとして利用することで、効率的にオブジェクトを生成することができます。
- Singleton パターン:アプリケーション全体で唯一のインスタンスを生成し、共有するパターンです。グローバルな状態を管理するような場合に有効です。
構造パターン
- Adapter パターン:互換性のないインターフェースを持つ2つのコンポーネントを繋ぎ合わせるパターンです。異なるシステム間でのデータ連携などに活用できます。
- Bridge パターン:オブジェクトの属性と機能を独立して変更できるようにするパターンです。柔軟性の高い設計を実現することができます。
- Composite パターン:複数のオブジェクトをツリー構造で階層的に構成するパターンです。全体と個々のオブジェクトを統一的に扱うことができます。
- Decorator パターン:オブジェクトに機能を追加していくパターンです。継承を使用せずに、オブジェクトの機能を拡張することができます。
- Facade パターン:複雑なシステムのインターフェースを簡素化するパターンです。初心者でも使いやすいシンプルなインターフェースを提供することができます。
- Flyweight パターン:頻繁に利用されるオブジェクトを共有することで、メモリ使用量を節約するパターンです。パフォーマンス向上に効果があります。
- Proxy パターン:オブジェクトへのアクセスを制御するパターンです。セキュリティやキャッシュなどの機能を実現するために利用できます。
振る舞いパターン
- Strategy パターン:アルゴリズムをオブジェクトとしてカプセル化するパターンです。アルゴリズムを柔軟に変更することができます。
- Observer パターン:オブジェクト間の依存関係を緩やかにするパターンです。イベント駆動型のプログラミングに適しています。
- Iterator パターン:コレクション内の要素を順番に処理するパターンです。様々な種類のイテレーションに対応することができます。
- Template Method パターン:アルゴリズムの骨格を共通化し、具体的な処理をサブクラスに任せるパターンです。コードの再利用性を高めることができます。
- Chain of Responsibility パターン:複数のオブジェクトに処理依頼を順番に伝えていくパターンです。責任の所在を明確にし、柔軟な処理分岐を実現することができます。
- State パターン:オブジェクトの状態によって動作を変えるパターンです。ステートマシンを実装する際に有効です。
- Memento パターン:オブジェクトの状態をスナップショットとして保存し、復元するパターンです。元に戻す機能などに活用できます。
各デザインパターンの詳細は以下の書籍で学ぶことができます。

この書籍は、オブジェクト指向プログラミングにおいて広く使われているデザインパターンについて、Java言語で書かれた短いサンプルプログラムとUMLを使い、オブジェクト指向プログラミングの初心者にもわかりやすく解説した技術書です。
デザインパターンを学びたい人にとっては必読書と言えるでしょう。
デザインパターンの各パターンは、単独で使用されることもあれば、組み合わせて使用されることもあります。
状況に応じて適切なパターンを選択し、オブジェクト指向のデメリット部分が問題にならないようにしましょう。
オブジェクト指向プログラミングの学習方法
オブジェクト指向プログラミングを学習するには、様々な方法があります。
以下に、代表的な方法をご紹介します。
オンラインでの学習リソース
- CodeCamp Javaマスターコース:オブジェクト指向で「社員情報管理システム」や「トランプゲーム」などの作成を通して、Javaを用いたWebアプリケーションの開発スキルを基礎から実践まで学べます。
ウズウズカレッジ Javaプログラミングコース:「Javaプログラミング」で「オブジェクト指向」を学ぶことができます。
- Udemy オブジェクト指向プログラミング(OOP)コース
:自分に合ったレベルのコースを自分のペースで学ぶことができます。分からないことがあれば、質問掲示板やコミュニティで他の受講者と交流して解決もできます。
プロジェクトを通した実践的な学び
独学で学習を進めるだけでなく、実際にプロジェクトを通してオブジェクト指向プログラミングを実践してみることも重要です。
- 個人プロジェクト:自分で考えた小さなプロジェクトに取り組んでみましょう。 例えば、簡単なゲームやツールなどを開発することで、オブジェクト指向プログラミングの概念を実際に使うことができます。
- オープンソースプロジェクトへの貢献:オープンソースプロジェクトに参加することで、他の開発者と一緒にオブジェクト指向プログラミングのコードを書くことができます。 これは、実践的な経験を積み、他の開発者から学ぶ良い機会となります。
効率的な学習のためのヒントとコツ
効率的に学習するには、なぜオブジェクト指向プログラミングで開発するのか?を理解することがとても大切です。

その答えをくれるのがこの書籍です。
オブジェクト指向プログラミングで開発するのが当たり前となった現在ですが、オブジェクト指向プログラミングが注目され始めた当時は、なぜオブジェクト指向プログラミングで開発すべきなのか?を説明できる人は少なかったと思います。
当時は流行っていたから、という安易な理由でオブジェクト指向プログラミングを採用していたシステムも少なくはなかったでしょう。
しかし、そんな理由で開発されたシステムが高い保守性や再利用性、拡張性で開発されたでしょうか?
上辺だけの理解でオブジェクト指向プログラミングを取り入れても、オブジェクト指向プログラミングの良さを100%発揮できたとは考えられません。
逆にオブジェクト指向プログラミングは扱いずらいと考えた人もいるでしょう。
オブジェクト指向プログラミングの良さを100%引き出すには、なぜオブジェクト指向プログラミングで開発するのか?を理解することがとても大切です。
この疑問を解決するには、オブジェクト指向プログラミングが主役に躍り出るまでの歴史を理解したうえで、オブジェクト指向の基本概念を理解することが非常に重要です。
本記事でもオブジェクト指向が主役に躍り出るまでの歴史と、オブジェクト指向の基本概念を紹介していますが、この書籍を参考にさせていただきました。
書籍ではもっと詳しく歴史や基本概要も書かれており、上流工程にも応用されたオブジェクト指向についても記載されています。
オブジェクト指向プログラミングを学ぶにあたって、とてもオススメできる内容になっていますので、一度手に取って、ぜひ読んでみてください。
まとめ
オブジェクト指向プログラミングは、ソフトウェア開発において非常に重要な手法です。
本記事では、オブジェクト指向プログラミングの基礎と重要な概念について説明しました。
オブジェクト指向プログラミングを理解することで、プログラムの保守性や拡張性を高め、より柔軟でメンテブルなソフトウェア開発が可能になります。
本記事で学んだことを活かして、ぜひオブジェクト指向プログラミングを活用したソフトウェア開発に取り組んでみてください。